C#学习笔记
入门及基础
代码结构
实例
先给出一个简单的c#代码结构:
1 | // 1. 命名空间:组织代码的逻辑容器(类似文件夹) |
代码结构拆解:
| 结构名称 | 作用说明 |
|---|---|
| 引用命名空间 | 引用一个工具包,类似可以看作c++中的头文件 |
| 命名空间 | 组织代码的逻辑容器(类似文件夹) |
| 类 | C#程序的基本单元(所有代码都在类里) |
| 函数 | 封装操作数据的逻辑 |
| 入口类 | 用来写Main方法的地方,可以和业务类放在同一个命名空间,也可以单独放,名称任意 |
| Main方法 | 程序的 “起点”,必须是 static void Main(string[] args),大小写固定 |
命名空间
命名空间是用来组织和重写代码、管理类的。他就像是一个工具包,类像是一件一件的工具,放在命名空间里方便取用。
语法:
1 | namespace 命名空间名 |
可以写n个命名空间,可以同名,可以分开写
不同命名空间中的相互使用需要引用命名空间或者指明出处。
- 引用命名空间
1 | Using 命名空间名 |
- 指明出处
1 | 使用的命名空间名.使用的类名 |
注意:
- 不同命名空间中允许有同名类
- 命名空间可以包裹命名空间
输入输出
输入内容:
1 | Console.ReadLine(); |
等待输入一行内容,输入回车键后结束输入。
1 | Console.ReadKey(); |
检测是否按键,只要按下任意一个键盘就会直接结束输入。
输出一句话:
1 | Console.WriteLine("yes"); // 自动换行 |
复杂数据类型
枚举
以下是一个枚举:
1 | enum E_MonsterType |
枚举成员默认的数值从 0 开始,依次递增 1,也可以自己赋值
枚举一般在namespace中申明,常见的使用方式是搭配switch-case来表示玩家状态、类型,以下是一个例子:
1 | E_MonsterType monsterType = E_MonsterType.Boss; |
枚举的类型转换:
枚举 ->
int:int i = (int)monsterType;
int-> 枚举:monsterType = 0;枚举 -> 字符串:
string str = monsterType.ToString();
字符串 -> 枚举:1
2
3// 参数1:转为的枚举类型
// 参数2:用于转换的对应枚举项的字符串
monsterType = (E_monsterType)Enum.Parse(typeof(E_monsterType), "other");
其中Enum是一个类名,直接使用它可以调用里面的方法。而之前遇到的enum是一个关键字,用于声明枚举。
数组
- 一维数组
- 声明:
1 | int[] arr1; |
1 | int[] arr2 = new int[5]; |
1 | int[] arr3 = new int[5]{ 1, 2, 3, 4, 5}; |
1 | int[] arr4 = new int[]{1, 2, 3, 4}; |
1 | int[] arr5 = {1, 2, 3, 4, 5, 6}; |
得到长度:
array.Length遍历数组:
遍历数组有两种方法,一种是for循环遍历,一种是使用语法糖foreach遍历:
先看for循环遍历:
1 | int[] arr = new int[5]; |
也可以用foreach遍历:
1 | int[] arr = new int[5]; |
其中,foreach是一种语法糖,并不是所有类型都支持用foreach遍历。不支持的类型的唯一本质是未满足可枚举规范(未实现 IEnumerable/IEnumerable<T> 接口,也无公有 GetEnumerator() 方法)。
迭代器就是为任意类型提供被foreach遍历的能力,让遍历变得简单、统一、灵活。
获取、修改、查找元素:与
c++一致增加、减少数组中的元素:不能直接增加或者减少,只能搬家
- 二维数组:
- 声明:
1 | int[,] arr; |
1 | int[,] arr2 = new int[n, m]; |
1 | int[,] arr3 = new int[3,3]{{1, 2, 3}, {1, 2, 3}}; |
1 | int[,] arr4 = new int[,] { {1, 2, 3}, {1, 2, 3}}; |
- 得到数组的行和列:
- 得到行:
array.GetLength(0); - 得到列:
array.GetLength(1);
- 得到行:
其中,传入的参数是维度索引:0对应第一维度,1对应第二维度,2对应第三维度。
值类型和引用类型
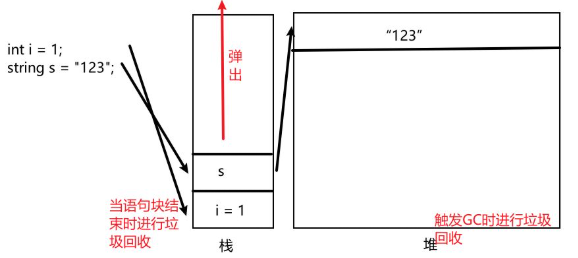
值类型
除了下述引用类型之外都是值类型。(其中与c++不同的是:float类型后加f,decimal类型后加m)
相互赋值时会把内容拷贝给对方
值类型存储在 栈空间:系统分配,小而快。
引用类型
引用类型总览
创建引用对象的时候都要使用new关键字
string- 数组
- 类
interface- 委托
引用类型存储在 堆空间:手动申请和释放,大而慢。
特殊的引用类型string
string非常特殊,它具备值类型的特征:他变我不变。
每次对string赋值都会重新开一个空间,会消耗相应的内存。
因此存在一个string的缺点,就是在不断重复赋值的过程中会不断产生内存垃圾,影响程序性能。
string相关方法
- 获取字符串指定位置
字符串本质是char[],因此可以获取字符串的指定位置元素:
1 | string str="大鱼飞九草"; |
- 转为char数组
1 | char[] chars = str.ToCharArray(); |
- 字符串拼接
- 方式一:用
+连接字符串 / 变量
1 | string name = "Alice"; |
- 方式二:内插字符串,在字符串前加
$,用{}包裹变量 / 表达式
1 | string name = "小明"; |
- 查找
- 正向查找字符位置
1 | str = "我是大鱼飞九草"; |
- 反向查找字符串位置
1 | str = "我是大鱼飞九草大鱼飞九草"; |
- 移除指定位置后的字符
- 移除指定位置后所有字符
1 | str = "我是大鱼飞九草"; |
- 从指定位置移除指定个数字符
1 | // 参数1:开始位置 |
- 替换指定字符串
1 | str = "我是大鱼飞九草"; |
- 大小写转换
- 转大写
1 | str = str.ToUpper(); |
- 转小写
1 | str = str.ToLower(); |
- 字符串截取
- 截取指定位置后的所有字符
1 | str = "大鱼飞九草"; |
- 从指定位置截取指定个数字符
1 | // 参数1:开始位置 |
- 字符串切割
1 | str = "1, 2, 3, 4, 5, 6, 7, 8"; |
StringBuilder
StringBuilder是C#提供的一个人用于处理字符串的公共类。使用它能实现修改字符串而不创建新的对象,需要频繁修改和拼接的字符串可以使用它,可以提升性能。
注意:使用前需要引用命名空间
- 初始化:
new
1 | using System.Text; |
StringBuilder存在一个容量的问题,每次往里面增加时会自动扩容获得容量,获得容量的方法:str.Capacity
- 相关操作
- 增
1 | // 方式1: |
- 插
1 | // 参数1:插入位置 |
- 删
1 | // 参数1:从哪个位置开始删 |
- 清空
1 | str.Clear(); |
- 查
1 | str[0] |
- 改
1 | str[0] = 'A'; |
- 替换
1 | // 参数1:要替换的位置 |
变量的生命周期
函数
ref和out
解决在函数内部改变外部传入的内容的问题。
ref和out的使用很简单,在申明参数和引用时在前面加上ref或out关键字即可。
以下是两个实例:
ref的使用:
1 | static void Main(string[] args) |
out的使用:
1 | static void ChangeValueOut(out int value) |
借此可以看出ref和out的区别:
ref传入的变量必须初始化,out不用out传入的变量必须在内部赋值,ref不用
变长参数和缺省参数
- 变长参数
- 关键字:
params - 作用:可以传入
n个同类型参数,n可以是0 - 注意:
params后面必须是数组,意味着只能是同一类型的可变参数- 变长参数只能有一个
- 必须在所有参数最后写变长参数
以下是一个变长参数应用的例子:
1 | int GetSum(int a, params int[] nums) |
- 缺省参数(默认参数)
- 作用:可以给参数默认值,使用时可以不传参,不传用默认的,传了用传的
- 注意:
- 可选参数可以有多个
- 可选参数只能写在所有参数的后面
以下是一个可选参数应用的例子:
1 |
|
函数重载
作用:
- 命名一组功能相似的函数,减少函数名的数量,避免命名空间的污染
- 提高程序可读性
特点:函数名相同,参数数量不同或数量相同,顺序不同
实例:
1 | static int CalcSum(int a, int b) |
辅助功能
预处理器指令
C#中的 预处理器指令(也叫编译器指令) 是一组以#开头的特殊语法指令,核心作用是指导C#在编译阶段执行特定的预处理逻辑。
编译器是一种翻译程序,它用于将源语言程序(某种序设计语言写成的,比如C#、C、C++、Java等语言写的程序)翻译为目标语言程序(二进制数表示的伪机器代码写的程序)。
以下是一些常见的预处理器指令:
#define:定义一个符号,类似一个没有值的变量#undef:取消define定义的符号,让其失效
以上两者都是写在脚本文件最前面,一般配合if指令使用,或配合特性。
#if#elif#else#endif
这一组指令和if语句规则一样,一般配合#define定义的符号使用,用于告诉编译器进行编译代码的流程控制。
除此之外,预处理器指令可以通过逻辑或和逻辑与进行多种符号的组合判断。
以下是一个实例:
1 |
|
#warning#error
这两条指令是告诉编译器报警告还是报错误,一般配合#if使用,以下是一个实例:
1 |
|
折叠代码
为了使编程时逻辑更加清晰,可以使用折叠代码。他能将包裹的代码折叠起来,避免代码太过凌乱。折叠代码属于编辑器指令,是仅由代码编辑器(如 Visual Studio、Rider、VS Code 等)识别和解析的特殊语法指令。
1 |
MyRegion 为折叠名称,可以自定义名称。
折叠代码本质上是编辑器提供给我们的预处理指令的工具,只会在编辑时有用。在发布代码后或者执行代码后会被删除。
异常捕获
为了避免代码报错时造成程序卡死的情况,可以使用异常捕获。
1 | //必备部分 |
将希望进行异常捕获的代码块放入try中,如果try中的代码出错了,会执行catch中的代码,来捕获异常。
finally表示,最后执行的代码,不管有没有出错都会执行其中的代码。
看默认值的方法
Console.WriteLine(defaute(int));
判断类型
F12进到类型的内部去查看
- 是c1ass就是引用
- 是struct就是值
另外,利用运算符typeof()还可以获得这个类的Type,其中,参数传入类的名字。Type是一个抽象基类。
变量本质及命名
- 变量的本质:
变量的本质是二进制,就是一堆0和1。(原因:数据传输是通过电信号来进行传递的,电信号只有开和关两种,因此这里使用0和1来表示。)
- 变量的命名规范:
驼峰命名法
首字母小写,之后的首字母大写。
例如:myName、vsCode、loveYou。帕斯卡命名法
所有单词首字母都大写(函数,类)。
例如:MyName、YourName。
- 变量 -> 常量:
在变量类型前面加上const前缀即可表示常量。
转义字符
转义字符的写法:
\+ 特定字符常见的转义字符:
| 转义字符 | 含义 |
|---|---|
\" |
双引号(普通字符) |
\' |
单引号(普通字符) |
\\ |
反斜杠本身 |
\n |
换行符 |
\t |
制表符(Tab 键,4 个空格) |
\0 |
空字符 |
化简写法:
如果你觉得转义字符麻烦,C# 提供了逐字字符串(在字符串前加 @),可以直接写特殊字符,无需转义:
1 | string path = @"C:\Code\Demo\test.txt"; |
核心
核心部分笔记参见C#之面向对象 | MeiMeiBlog
进阶
简单的数据结构类
数据结构主要研究数据如何在计算机中组织和存储,以及对这些数据进行操作。
主要包含以下三大板块:
线性结构
- 数组(
Array) - 链表(
Linked List) - 栈(
Stack) - 队列(
Queue)
- 数组(
非线性结构
- 树(
Tree) - 图(
Graph)
- 树(
集合与映射
- 哈希表(
Hash Table) - 字典(
Dictionary)
- 哈希表(
ArrayList 动态数组
Array、ArrayList和List<>的区别与联系:
| 类型 | 含义 | 特点 |
|---|---|---|
Array |
数组 | 最基础的原生数组类型,如int[]、string[]。固定长度,强类型(声明时指定元素类型) |
ArrayList |
动态数组 | 基于Array封装的可变长度的数组。弱类型(可存储各种类型的元素) |
List<> |
泛型列表 | 完美结合Array和ArrayList(可变长度 + 强类型) |
ArrayList是一个C#为我们封装好的类,他的本质是object[]
- 申明
1 | using System.Collections; |
- 增删查改
- 增
增加有两种方式,分别是一个一个的增加,也可以按范围增加。
一个一个的增加:
1 | array.Add(1); // 增加一个int型 |
按范围增加:
1 | ArrayList arrayList2 = new ArrayList(); |
- 插
1 | // 参数1:要插入的位置 |
- 删
1 | // 按值删除 从头找 |
- 查
得到指定位置的元素:
1 | arrayList[0] |
查看元素是否存在:
1 | if(arrayList.Contains("1234")) |
正向查找元素位置:
1 | // 参数:要查找的元素 |
反向查找元素位置:
1 | // 返回值:从头开始的索引数 |
- 改
1 | arrayList[0] = "999"; |
遍历
得到长度:
arrayList.Count得到容量:
arrayList.Capacity,可以避免产生过多垃圾
方法1:
1 | for(int i = 0; i < arrayList.Count; i ++) |
方法2:
1 | foreach(object item in arrayList) |
Stack 栈
Stack(栈)是一个C#为我们封装好的类,它的本质也是object[]。他的特殊之处在于封装了特殊的存储规则:先进后出。
- 申明
1 | using System.Collections; |
- 增删查改
- 增
1 | // 只能一个一个的压入 |
- 取
1 | v = stack.Pop(); |
- 查
栈无法查看指定位置的元素,只能查看栈顶的内容。
1 | v = stack.Peek(); |
还可以看元素是否存在于栈中:
1 | if(stack.Contains("123")) |
- 改(清空)
栈无法改变其中的元素只能压(存)和弹(取),实在要改只有清空
1 | stack.Clear(); |
遍历
- 得到长度:
stack.Count
- 得到长度:
因为栈没有索引器,故只能用foreach遍历,得到的顺序是从栈顶到栈底。
1 | foreach(object item in stack) |
不过,也可以将栈转为object[]遍历:
1 | object[] array = stack.ToArray(); |
- 循环弹栈
只要栈中存在元素,便不断弹出。
1 | while(stack.Count > 0) |
Queue 队列
Queue是一个c#为我们封装好的类,它的本质也是object[]数组。只是封装了特殊的存储规则:先进先出。
- 申明
1 | using System.Collections; |
- 增删查改
- 增
1 | // 只能一个一个的入队 |
- 取
1 | object v = queue.Dequeue(); |
- 查
查看队列头部元素(不会移除)
1 | v = queue.Peek(); |
查看元素是否存在于队列中
1 | if(queue.Contains(1.4f)) |
- 改(清空)
队列无法改变其中的元素只能进出队列,实在要改只有清空
1 | queue.Clear(); |
遍历
- 得到长度:
queue.Count;
- 得到长度:
用foreach遍历:
1 | foreach(object item in queue) |
也可以将队列转为object[]
1 | object[] array = queue.ToArray(); |
- 循环出列
1 | while(queue.Count > 0) |
Hashtable 哈希表
Hashtable是基于键的哈希代码组织起来的键值对。它的主要作用是提高数据查询的效率,使用键来访问集合中的元素。
- 申明
1 | using System.Collections; |
- 增删查改
- 增
1 | // 参数1:键 object类型 |
注意:不能出现相同键
- 删
只能通过键去删除,删除不存在的键没反应。
1 | hashtable.Remove(1); |
或者直接清空:
1 | hashtable.Clear(); |
- 查
通过键查看值,如果找不到会返回null:
1 | Console.WriteLine(hashtable[1]); |
查看是否存在,可以通过键查看、也可以通过值查看,我们先来看通过键查看:
1 | // 方法1 |
也可以通过值查看:
1 | if(hashtable.ContainsValue(12)) |
- 改
只能改键对应的值内容,无法修改键。
1 | hashtable[1] = 100.5f; |
遍历
- 得到键值对对数:
hashtable.Count;
- 得到键值对对数:
遍历所有键:
1 | foreach(object item in hashtable.Keys) |
遍历所有值:
1 | foreach(object item in hashtable.Values) |
键值对一起遍历:
1 | foreach(DictionaryEntry item in hashtable) |
迭代器遍历法:
迭代器就是为任意类型提供被foreach遍历的能力,让遍历变得简单、统一、灵活。
1 | IDictionaryEnumerator myEnumerator = hashtable.GetEnumerator(); |
泛型及常用泛型数据结构类
泛型
- 用泛型可以实现复用代码的目的,改变类型不过其中的逻辑一样
- 泛型相当于类型占位符
- 定义类或方法时使用替代符代表变量类型;当真正使用类或者方法时再具体指定类型
- 泛型的分类
泛型可以分为泛型类、泛型接口、和泛型函数。
泛型类
申明语法:
1 | class 类名<泛型占位字母> |
以下是一个具体的例子:
1 | // 申明 |
泛型接口
申明语法:
1 | interface 接口名<泛型占位字母> |
以下是一个具体的例子:
1 | // 申明 |
泛型函数
申明语法:
1 | 函数名<泛型占位字母>(参数列表) |
注意:泛型占位字母可以有多个,用逗号分开
- 普通类的泛型方法
1 | // 普通类 |
另外,泛型占位符还可作为返回值。
- 泛型类的泛型方法
1 | // 泛型类 |
其中,TestFun1(T t)这个函数不是泛型方法。因为T是泛型类申明的时候就指定的。再使用这个函数的时候我们就不能再去动态的变化了。
泛型约束
泛型约束可以让泛型的类型有一定的限制。要想new一个T,必须加约束,因为无法得知是否可以访问(private)
关键字:
where分类:
| 约束类型 | 表现方式 |
|---|---|
| 值类型 | where 泛型字母:struct |
| 引用类型 | where 泛型字母:class |
| 存在无参非抽象公共构造函数 | where 泛型字母:new() |
| 某个类本身或者其派生类 | where 泛型字母:类名 |
| 某个接口的派生类型 | where 泛型字母:接口名 |
| 另一个泛型类型本身或者派生类型 | where 泛型字母:另一个泛型字母 |
注意:多个约束可以组合使用,例如:
1 | class Test<T> where T: class, new() |
也存在多个泛型有不同约束的情况,例如:
1 | class Test<T, K> where T:class, where K:struct |
常用泛型数据结构类
List<> 列表
List<>是一个c#为我们封装好的类,它的本质是一个可变类型的泛型数组。
- 申明
1 | using.System.Collections.Genertic; |
- 增删查改
- 增
单个增:
1 | list.Add(1); |
批量增:
1 | list.AddRange(1234); |
如果说,这个泛型对应的是一个列表,也可以通过这种方式直接将整个列表添加进来。
- 插
1 | // 参数1:插入位置 |
- 删
移除指定元素:
1 | list.Remove(1); |
移除指定位置的元素:
1 | list.RemoveAt(0); |
清空:
1 | list.Clear(); |
- 查
得到指定位置的元素:
1 | Console.WriteLine(list[0]); |
查看元素是否存在:
1 | if( list.Contains(1) ) |
正向查找元素位置:
1 | // 找到 返回位置 |
反向查找元素位置:
1 | // 找到 返回位置 |
- 改
1 | 1ist[0]=99; |
遍历
- 得到长度:
list.Count - 得到容量:
list.Capacity
- 得到长度:
用for循环遍历:
1 | for(int i = 0; i < list.Count; i ++) |
用foreach遍历:
1 | foreach(int item in list) |
List排序
List自带排序方法:
1 | // 系统自带的变量(int、double)排序方法,默认升序 |
自定义类排序:
自定义类排序的重点是将类继承IComparable<T>接口,IComparable<T> 是泛型比较接口,核心作用是为自定义类定义排序规则
1 | class Item : IComparable<Item> |
其中,CompareTo()这个函数有特定的规则,这是行业决定的,不能自己修改:
| 返回值 | 含义 | 排序结果 |
|---|---|---|
负数(<0) |
当前对象 < 待比较对象(this < other) |
当前对象排在前面 |
0 |
当前对象 == 待比较对象(this == other) |
两个对象排序位置相同 |
正数(> 0) |
当前对象 > 待比较对象(this > other) |
当前对象排在后面 |
Lambda表达式 + 三目运算符
1 | shopItems.Sort((a, b) => {return a.id > b.id ? 1 : -1;}); |
Dictionary<> 字典
可以将Dictionary<>理解为拥有泛型的Hashtable,它也是基于键的哈希代码组织起来的键/值对。键值对类型从Hashtable的object变为了可以自己制定的泛型。
- 申明
1 | using System.Collections.Generic; |
- 增删查改
- 增
1 | dictionary.Add(1,"123"); |
注意:键名不能重复
- 删
只能通过键去删除,删除不存在键没反应。
1 | dictionary.Remove(1); |
也可以直接清空。
1 | dictionary.Clear(); |
- 查
通过键查看值(查不到会直接报错):
1 | Console.WriteLine(dictionary[2]); |
查看是否存在有两种方法,根据键检测、或者根据值检测。
先来看根据键检测:
1 | if(dictionary.ContainsKey(1)) |
再看根据值检测:
1 | if (dictionary.ContainsValue("123")) |
- 改
1 | dictionary[1] = "555"; |
遍历
- 得到键值对对数:
dictionary.Count
- 得到键值对对数:
遍历所有键:
1 | foreach(int item in dictionary.Keys) |
遍历所有值:
1 | foreach(string item in dictionary.Values) |
键值对一起遍历:
1 | foreach(KeyValuePair<int,string> item in dictionary) |
LinkedList<> 双向链表
LinkedList是一个c#为我们封装好的类, 它的本质是一个可变类型的泛型双向链表。
- 申明
1 | using System.Collections.Generic; |
- 增删查改
- 增
在链表尾部添加元素:
1 | linkedList.AddLast(10); |
在链表头部添加元素:
1 | linkedList.AddFirst(20); |
在某一个节点之后添加一个节点:
1 | //要指定节点先得得到一个节点 |
在某一个节点之前添加一个节点:
1 | //要指定节点先得得到一个节点 |
- 删
移除头节点:
1 | linkedList.RemoveFirst(); |
移除尾节点:
1 | linkedList.RemoveLast(); |
移除指定节点:
1 | //无法通过位置直接移除,只能通过值移除 |
清空:
1 | linkedList.Clear(); |
- 查
头节点:
1 | LinkedListNode<int> first = linkedList.First; |
尾节点:
1 | LinkedListNode<int> last = linkedList.Last; |
找到指定值的节点:
1 | //无法直接通过下标获取中间元素 |
判断是否存在:
1 | if(linkedList.Contains(1)) |
- 改
1 | //要先得再改得到节点,再改变其中的值 |
- 遍历
foreach遍历:
1 | foreach(int item in linkedList) |
通过节点遍历有两种方法,从头到尾和从尾到头,下面先来看从头到尾遍历:
1 | LinkedListNode<int> nowNode = linkedList.First; |
再来看从尾到头:
1 | LinkedListNode<int> nowNode = linkedList.Last; |
泛型栈和队列
- 申明:
1 | using System.Collections.Generic; |
- 使用:和简单数据结构类中的
Stack、Queue一样
委托、事件与Lambda表达式
委托
委托是函数的容器,用来存储、传递函数,可以理解为像指针一样,他装函数的意思是存储了函数的引用,因此调用委托时就可以调用函数本身。他能让你的程序不再死等(异步回调),还能一键通知所有人(多播)。本质是一个类,用来定义函数的类型(返回值和参数的类型)。不同的函数(方法)必须对应和各自”格式”一致的委托。
关键字:
delegate语法:
1 | 访问修饰符 delegate 返回值 委托名(参数列表); |
以下是一个实例:
1 | // 委托一般写在 namespace 中 |
注意:
- 访问修饰默认不写为
public,一般使用public - 委托不能重名
除了这种自定义委托外,还有系统定义委托,其实我们更常用系统定义好的委托:
要用系统定义委托,需要引用以下命名空间:
1 | using System; |
- 无参无返回
1 | Action action = Fun; |
- 可以指定返回值类型的 泛型委托
1 | Func<T> funcT = Fun2; |
- 可以传
n(1~16)个参数的 泛型委托
1 | Action<T, K> action = Fun3; |
- 可以传
n(1~16)个参数且有1个返回值的 泛型委托
1 | // 前面写参数 |
委托可以作为类的成员:
1 | class Test |
也可以作为函数的参数:
1 | class Test |
另外,委托变量可以存储多个函数。这样就可以实现同时通知多个函数调用的功能,这种委托叫多播委托。
多播委托的一些操作:
- 增加函数
1 | MyFun ff = Fun; |
- 移除函数
1 | // 多减不会报错 无非就是不处理 |
- 清空委托
1 | ff = null; |
事件
事件是基于委托的存在,事件是委托的安全包裹,让外部只能+= \ -= 订阅 \ 取消订阅,防止外部随意置空、调用委托。让委托的使用更具有安全性。事件是一种特殊的变量类型。
关键字:
event语法:
1 | 访问修饰符 event 委托类型 事件名; |
事件的使用和委托一模一样。
事件不同于委托的是:它只能作为成员在于类、接口以及结构体中。
区别1:委托可以在外部赋值(如t.myFun = null),而事件不行,但可以加减函数(如:t.myEvent += Fun)。
区别2:委托可以在外部调用(如:t.myFun()),而事件不行。
匿名函数
匿名函数就是没有名字的函数,它主要是配合委托和事件进行使用,脱离委托和事件是不会使用匿名函数的。
- 匿名函数语法
1 | delegate(参数列表) |
以下是几个Unity封装好的委托与匿名函数的使用:
- 无参无返回值
1 | // 申明Action委托 |
- 有参
1 | // 申明Action<,>委托 |
- 有返回值
1 | // 申明Func<>委托 |
匿名函数的作用是使代码更加简洁,不过他也有缺点,因为不知道名字,将匿名函数添加到委托或事件容器后不能单独移除。
Lambda表达式
Lambda表达式可以被理解为匿名函数的简写,除了写法不同外,使用上和匿名函数一模一样,都是和委托或者事件配合使用的。
- Lambda表达式语法
1 | (参数列表) => |
具体使用就是和委托类型保持一致,配合使用就可以。
- 闭包
闭包是指内层的函数可以引用包含在它外层的函数的变量,即使外层函数的执行已经终止。
以下是一个实例:
1 | // 外部函数(构造函数) |
协变与逆变
协变和逆变是C#为泛型委托、接口设计的类型转换规则,核心目的是使泛型类型的赋值更灵活。
协变,用out关键字标记。允许子类泛型类型赋值给父类泛型类型(如Func<Dog> -> Func<Animal>)。
逆变,用in关键字标记。允许父类泛型类型赋值给子类泛型类型(如Func<Animal> -> Func<Dog>)。
其中,out和in都是用于在泛型中修饰泛型字母的。
返回值和参数
- 用
out修饰的泛型只能作为返回值
1 | delegate T Testout<out T>(); |
- 用
in修饰的泛型只能作为参数
1 | delegate void TestIn<in T>(T t); |
结合里氏替换原则理解
协变:和谐的变化,自然的变化。因为里氏替换原则父类可以装子类,所以子类变父类。比如
string变成object感受是和谐的。逆变:逆常规的变化,不正常的变化。因为里氏替换原则父类可以装子类但是子类不能装父类,所以父类变子类。比如
object变成string感受是不和谐的。
多线程
进程就是指一个应用程序。进程之间相互独立运行,互不干扰;也可以相互访问、操作。
线程是指操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位,Main函数就是主线程,我们目前都在主线程中写程序。可以简单理解为代码从上到下运行的一条“管道”。
而多线程就是可以同时运行代码的多条“管道”。
相关操作
想用线程,需要引用命名空间:
1 | using System.Threading; |
- 申明一个新的线程
1 | Thread t = new Thread(NewThreadLogic); |
注意:线程执行的代码 需要封装到一个函数中
- 启动线程
1 | t.Start(); |
- 设置为后台线程
1 | t.IsBackground = true; |
设置为后台线程的原因是如果不设置为后台线程,可能导致进程无法正常关闭。
- 关闭释放一个线程
情况1 不是死循环 t = null;
情况2 是死循环
有两种方式:
1 | // 方式1:死循环中bool标识 |
- 线程休眠
1 | // 参数是毫秒数 1s = 1000ms |
另外,多个线程是共享内存的。所以要注意当多线程同时操作同一片内存区域时,可能会出问题。
可以通过加锁(lock)的形式避免问题
1 | // lock里面必须填引用类型 |
多线程的意义是处理一些复杂耗时的逻辑,比如寻路、网络通信等问题。
反射
反射的定义
反射是指一个运行的程序查看其它程序集或者自身元数据的行为。
其中,程序集是经由编译器编译得到的,供进一步编译执行的那个中间产物;在WINDOWS系统中,它一般表现为后缀为.dll(库文件)或者是.exe(可执行文件)的格式。元数据是用来描述数据的数据,程序中的类,类中的函数、变量等等信息就是程序的元数据;有关程序以及类型的数据被称为元数据,它们保存在程序集中。这个概念不仅仅用于程序上,在别的领域也有元数据。
- 运用反射的链接:
1 | using (命令行链接) / gameobject.getcomponent<类型>(方法链接其他程序集) |
- 语法相关:见后续分节
Type 信息类
Type是类的信息类,它是反射功能的基础,是访问元数据的主要方式,使用Type的成员获取有关类型申明的信息。
- 获取
Type
方法1 万物之父object中的GetType()方法
1 | int a = 42; |
方法2 通过typeof关键字传入类名获得
1 | Type type2 = typeof(int); |
方法3 通过类的名字获得
1 | Type type3 = Type.GetType("System.Int32"); |
其中,方法三中的Type是C#里默认的工具。
注意:类名必须包含命名空间
获取Type后便可以获得类的各种信息:
需要引用命名空间:
1 | using System.Reflection; |
- 程序集信息
1 | Console.WriteLine(type.Assembly); |
- 所有公共成员
1 | MemberInfo[] infos = type.GetMembers(); |
- 类中的构造函数
可以获取所有的构造函数:
1 | ConstructorInfo[] ctors = type.GetConstructors(); |
也可以获取其中一个构造函数并执行:
得构造函数传入Type[],数组中内容按顺序是参数类型;
执行构造函数传入object[],表示按顺序传入的参数。
1 | // 1.得到无参构造 |
- 公共成员变量
得到所有成员变量:
1 | FieldInfo[] fieldInfos = type.GetFields(); |
得到指定名称的公共成员变量:
1 | // 参数:要得到的那个成员变量名 |
通过反射获取和设置对象的值:
1 | // 获取 |
- 公共成员方法
得到所有方法:
1 | MethodInfo[] methods = strType.GetMethods(); |
得到并调用指定名称的方法:
1 | // 得到指定方法 |
- 泛型类型
1 | Type fieldType; |
Assembly 加载其它程序集
Assembly主要用来加载其它程序集,加载后才能用Type来使用其它程序集中的信息。
接下来介绍三种加载程序集的函数:
- 加载同一文件下的其他程序集:
1 | Assembly assembly = Assembly.Load("程序集名称"); |
- 加载不在同一文件下的其他程序集:
方法1
1 | Assembly assembly2 = Assembly.LoadFrom("包含程序集清单的文件名称或路径"); |
方法2
1 | Assembly assembly3 = Assembly.LoadFile("要加载的文件的完全限定路径"); |
下面是一个综合运用的实例:
1 | using System.Reflection; |
Activator 快速实例化对象
Activator可以将Type对象快速实例化对象。
- 无参构造
1 | Type testType = typeod(Test); |
- 有参构造
1 | Type testType = typeod(Test); |
类库文件
类库文件(.dll)可以看成一种代码仓库,它提供给使用者一些可以直接拿来用的变量、函数或类。我们可以创建类库文件来建立引用对象,他就是一个用来引用的对象,无法直接运行。
创建类库文件:新建控制台程序 -> 创建xx库文件。
特性
特性的本质是个类。我们可以利用特性类为元数据(一个类、成员变量、成员方法)添加额外信息。之后可以通过反射来获取这些额外信息。
自定义特性
特点:继承特性基类
Attribute命名:
类的含义+Attribute
以下是一个实例:
1 | class MyCustomAttribute : Attribute |
- 限制自定义特性的使用范围
通过为特性类加特性限制其使用范围,具体操作如下:
1 | // 参数1:AttributeTargets —— 特性能够用在哪些地方 |
其中,|是位或运算符,这里表示可以同时使Class和Struct都加上特性。不用&&的原因是:这二者都是枚举类型,对应二进制数,要用|对其操作,而&&对应bool类型。
特性的使用
基本语法如下:
1 | [特性名(参数列表)] |
其中,系统自动省略了特性名中的Attribute。
本质上就是在调用特性类的构造函数,它可以写在类、函数、变量上一行,用于表示他们具有该特性信息。
以下是一个实例:
1 | [] |
关于特性还有以下几个方法:
- 判断是否使用了某个特性
1 | // 参数1:特性的类型 |
- 获取
Type元数据中的所有特性
1 | object[] array = t.GetCustomAttributes(true); |
系统自带特性
- 过时特性:用于提示用户使用的方法等成员已经过时,建议使用新方法
1 | // 参数1:调用过时方法时,提示的内容 |
- 调用者信息特性(有3种):用于
try-catch中的catch显示捕获的异常信息的位置,一般用在标记函数的参数。
需要引用命名空间:
1 | using System.Runtime.CompilerServices; |
以下是3种调用者信息特性的写法:
1 | // 1.哪个文件调用 |
注意:这三个特性在使用时都需要给被使用的变量赋一个默认值,如下所示:
1 | []string fileName = ""; |
- 条件编译特性:用于有时想执行有时不想执行的代码,和预处理器
#define配合使用(见 入门及基础 / 辅助功能 / 预处理器指令)
1 | using System.Diagnostics; |
- 外部dll包特性:用来标记非
.Net(C#) 的函数,表明该函数在一个外部的DLL(可执行代码文件)中定义,一般用来调用C或者C++的包写好的方法。
1 | using System.Runtime.InteropServices; |
其中,extern表示该方法的实现是在外部的非托管代码中,即存在于指定的DLL中。
迭代器
迭代器是一种设计模式,提供一个方法顺序访问一个聚合对象中的各个元素,而又不暴露其内部的标识。想使用foreach遍历,必须实现迭代器。
比如我有一个自定义类,它里面有一个私有的List[],通过实现迭代器,就可以对外暴露遍历的能力,外部不需要知道数组的存在、不需要知道数组的索引 / 长度,只需要用 foreach 就能逐个拿到数组里的元素。
接下来,分别介绍标准迭代器的实现方法和语法糖的形式。
标准迭代器的实现方法
关键接口:IEnumerator, IEnumerable
1 | using System.Collections; |
foreach本质:
- 先实现
in后面这个对象的IEnumerable接口,调用GetEnumerator方法,获取IEnumerator枚举器 - 执行得到这个
IEnumerator对象中的MoveNext方法,只要MoveNext方法返回值为true就会得到Current,然后赋值给item
用yield return语法糖实现迭代器
yield return是C#提供给我们的语法糖,可以简化迭代器的实现。其中的关键接口只有IEnumerable。
- 为普通类实现迭代器
1 | using System.Collections; |
其中,yield return可以理解为暂时返回,保留当前状态。其实本质还是系统生成了标准迭代器中的MoveNext()等方法。
- 为泛型类实现迭代器
1 | class CustomList<T> : IEnumerable |
常见语法糖
var隐式类型
var是一种编译期类型推断关键字(语法糖),它可以用来表示任意类型的变量,但不是一个实际的数据类型。
注意:
var不能作为类的成员使用,因为类的成员必须指明变量类型,只能用于临时变量申明时,也就是一般写在函数语句块中var必须初始化
需要特别说明的是, var只是用来写代码时偷懒的工具,一旦确定类型就不可变,例如:
1 | var num1 = 100; // 编译期推断num1的类型是int |
而object 是C#所有类型的基类,类型确定后也可以改变,例如:
1 | object num2 = 100; // num2的类型是object,值是装箱后的int |
除此之外,var变量还可以申明为自定义的匿名类,实例如下:
1 | var v = new { age = 10, money = 11, name = "小明" }; |
注意:里面不能写函数相关的内容,只有成员变量
设置初始值
- 设置对象初始值
申明对象时可以通过直接写大括号的形式初始化公共成员变量属性。
以下是一个实例:
1 | Person p = new Person(100){ sex = true, Age = 19, Name = "meimei酱" }; |
- 设置集合初始值
申明集合对象时也可以通过大括号直接初始化内部属性。
以下是一个实例:
1 | Dictionary<int, string> dic = new Dictionary<int, string>() |
可空类型
值类型不能赋值为空null,但是申明时加上一个?就可以了,具体如下:
1 | int? c = null; |
与可空类型相关的方法如下:
- 判断是否为空
1 | if(c.HasValue) |
- 安全获取可空类型值
1 | int? value = null; |
- 判断是否为空
1 | o?.ToString(); |
相当于:
1 | object o = null; |
还有一个与之相关的符号 —— 空合并操作符 ??
语法如下:
1 | 左边值 ?? 右边值 |
使用结果是:如果左边值为null就返回右边值,否则返回左边值。
单句代码省略写法
语法如下:
- 属性中
1 | public string Name |
- 函数中
1 | public int Add(int x, int y) => x + y; |
也可以像这样:
1 | public void Speak(string str) => Console.WriteLine(str); |